Mitigating supply chain risk
After widespread coverage, the CrowdStrike outage from 19 July 2024 hardly needs an introduction.
But as a reminder, here are some key facts about the CrowdStrike incident:
- CrowdStrike is a publicly listed security company, which provides security software to – among many other large organisations – Microsoft.
- The primary incident was a breach of integrity and availability, not confidentiality. (Learn more about the CIA triad here.)
- The outage was caused by a bad security update rolled out by CrowdStrike.
- According to Microsoft, this update affected around 8.5 million Windows devices.
- The total direct financial loss for US Fortune 500 companies, excluding Microsoft, is estimated at $5.4 billion (about £4.2 billion).
- The weighted average loss is $44 million (£34 million), ranging from $6 million to $143 million (£5 million – £111 million).
- According to Parametrix, an insurance company specialising in Cloud outages, cyber insurance policies likely cover up to 10–20% of losses only.
- In just a few days, between 18 and 22 July, CrowdStrike ($CRWD) lost 23.1% of its share price.
Without question, this is one of the most expensive IT outages to date, with significant global impact.
To find out more about what we can learn from the event, and protect ourselves from ‘Strike 2’, we talked to our information security manager, Adam Seamons.
In this interview
A low-tech but laborious fix
The full financial impact of the CrowdStrike incident is becoming clearer, and the figures are staggering. The weighted average loss for Fortune 500 companies [$44 million] is on a par with some of the biggest ransomware payouts ever – and this IT outage wasn’t caused by a malicious attack!
This cost was largely due to the operational impact, and the labour-intensive nature of the solution. Could you elaborate?
The fix was predominantly low tech. We’re not talking a cyber attack, requiring specialists to figure out exactly what happened [digital forensics] and cautiously bring your systems back up.
This was simply a case of a software supplier deploying a bad software update. It affected a broad install base – i.e. lots of customers [organisations], systems, and individual users and devices.
Once applied, the update crashed the system. The end user would receive the dreaded ‘blue screen of death’. Then, if they attempted to reboot, the system would give another error and fail to load the operating system.
To fix that, someone would have to log in to the system via ‘safe mode’ [safe mode, repair mode]. Then, they could roll back the system configuration to a pre-update state, or remove the problematic files.
Why is rebooting in safe mode such a laborious fix?
It’s generally a manual task, which needs to be performed on every single computer.
Worse, for systems using BitLocker Drive Encryption, you also need to enter a special key to unlock your encrypted drive if you can’t unlock the drive using your normal method. That’s a 48-digit password – 8 pairs of 6 digits.
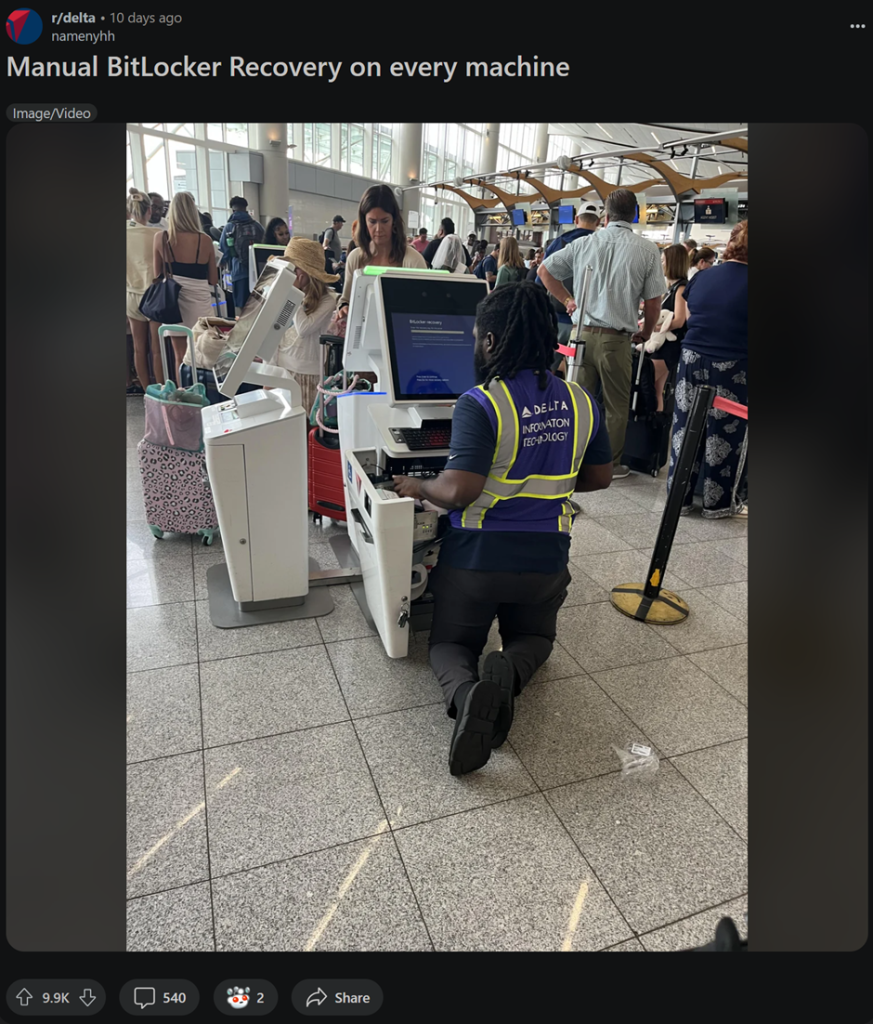
One image that stuck with me was an IT engineer in an American airport, wearing a hi-vis jacket, kneeling in front of a terminal. All he did is manually enter this lengthy recovery key, then remove the patch.

Source: Reddit
To put it another way, the difficulty was finding sufficient manpower to do this for every single system – quickly. How many boots can you put on the ground?
Because even though the fix was relatively simple, you still needed a technical member of staff for it. And you needed them on site.
That’s very different to how a lot of IT support can be delivered today – remotely and, to a large extent, automated.
If using encryption adds an extra step to the recovery, is that why security-conscious industries were hit harder than others? [Aviation, banking, healthcare, etc.]
Yes. Worse, the BitLocker keys were probably stored on an affected server – so, it wasn’t just a matter of typing in a lengthy key, but getting the keys in the first place.
That said, with supply chains as complex as they are now, the next time, the worst affected industries could be entirely different.
Supply chain risks
Can you compare the CrowdStrike incident to other disruptive events?
From an IT point of view, I can’t recall similar disruptions.
Perhaps the best comparison is the Suez Canal blockage from 2021. The cause of that incident was almost silly – a boat gets stuck in a canal! But it had far-reaching impact.
As a direct result of that blockage, oil couldn’t reach its destination, manufacturers couldn’t get crucial parts, and so on. The world then needed many months to catch up – all because of a stuck boat!
The CrowdStrike situation was similar in that a small, uncomplicated issue caused huge disruption.
And that’s because complex supply chains are so common now?
Yes. In the physical world, many organisations deal with global suppliers. Having parts come in from multiple countries, if not continents, is more common than not.
As for the IT angle: with CrowdStrike, even if you don’t have a system running its software directly, you might rely on a different third party – like Microsoft – that does use it. If your supplier then can’t connect to the sub-processor, that’ll have a knock-on effect on you, too.
And again, the thing that went wrong for the sub-processor in this scenario – CrowdStrike – was simple: a bad update.
I’ve worked in IT for nearly 20 years – bad updates that knock your systems happen all the time.
But because of today’s interconnected nature – all this reliance on hardware manufacturers, Cloud service providers, and so on – this simple, common issue can have a massive knock-on effect. As the CrowdStrike situation showed us, of course.
How to secure your supply chain
With supply chains as complex as they are, can organisations really defend themselves against CrowdStrike-type scenarios? And if so, how?
It’s tricky. Having a business continuity plan [BCP] is invaluable, but you can’t foresee every type of event. Back in 2020, most organisations hadn’t planned for a pandemic, for example.
The risks for which you prepare reflect your best guess only.
So, for business continuity management [BCM] purposes, it’s better to come at it from the other direction:
- What processes [business activities] are critical to your organisation?
- Which suppliers support these critical processes?
- What systems are critical to these processes?
- Do you have any single points of failure?
- What compensating controls, or plan Bs, can you implement to mitigate a failure?
Think about what you want to protect or preserve, and how to protect them. Identifying the risks at a high level is, without question, an important exercise. That means asking stuff like:
- What happens if this process stops?
- What happens if that data is wrong or unavailable?
But for this exercise to be useful, the organisation must put a lot of thought into these questions, along with honest self-reflection.
After identifying key suppliers, what are the next steps?
Find out what your critical suppliers’ business continuity plans are – how proactive are they about service availability?
Contracts are the other big thing to pay close attention to – what guarantees do your suppliers provide on availability, and can you recoup damages if those terms are breached? What clawback provisions or liability protections do those contracts have?
Then there’s insurance. Cyber insurance is becoming more common, but carefully check what you’re covered for – is it malicious cyber incidents only, or also IT glitches like this CrowdStrike outage?
I suspect some organisations will be in for a nasty surprise in the weeks and months to come, finding out that their insurance doesn’t cover them for a non-malicious IT glitch such as this.
What about diversification? So, spreading the risk by relying on multiple suppliers?
That helps, but it has limitations. For example, when I first worked in IT, we used a backup telephone line for our Internet.
But whether you use BT, Sky, or someone else, the cable goes back to the same exchange. Meaning that any interruption may well be down to the same cable, so you’re in trouble either way.
So, what can you do about it? Use a combination of cable and satellite Internet providers, perhaps.
But this isn’t feasible for every organisation, particularly as these are extreme events. Plus, often, the outlier events are the ones that really have an impact. That makes it difficult to plan and justify costs to senior management.
What precautions are more easily justifiable to senior management?
Some organisations could justify precautions like having spare capacity, parts and/or devices.
If you’re a remote organisation, for example, and you have a device suffering from the BSOD [blue screen of death], the quickest way to resolve this might be to provide the user with another device. However, being able to do that requires keeping extra devices in stock.
But that too isn’t something every organisation is prepared to do. Many prefer to keep their operations as lean as possible – which is understandable if you’re small, or struggling to justify budgets.
Again, diversity and flexibility help. Where you can’t be robust, try to be resilient. Try to give yourself flexibility – i.e. multiple response options.
ISO 22301 is the international standard for business continuity management. How can it help organisations in their business continuity planning?
ISO 22301 provides a useful framework – a starting point for planning your business continuity. Think of it as a base to access and plan your measures. However, it doesn’t mandate specific measures, so you’ll have to look elsewhere for those.
That said, the Standard is a good resource. It helps you approach business continuity planning in a sensible, structured manner. It’ll also remind you how business continuity isn’t just about IT availability.
As an example, if you’re a training provider, then sure – your streaming software going down or a laptop breaking are potential problems. But so is the human element – what if the trainer is ill? What if they can’t get to the location due to a transport issue?
ISO 22301, if implemented properly, will remind you of these ‘mundane’ types of questions.
Want to learn more about ISO 22301?
Get a comprehensive introduction to the Standard, and learn about business continuity management fundamentals, in our free green paper.

Page 4 of Business Continuity and ISO 22301 – Preparing for disruption
You’ll also get a step-by-step overview of how to implement a BCMS (business continuity management system) in line with best practice.
Consider integrity and availability too – not just confidentiality
The CrowdStrike story was heavily covered in the news – perhaps in part because it makes a change from the ‘usual’ breaches of confidentiality. But this incident was a failure of availability [and integrity]. What are your views on that?
In the press, confidentiality is the big focus. You don’t want that type of breach, because it damages your brand – you could be fined under the GDPR, for example [General Data Protection Regulation].
But then we get an incident like this, which is massive and may well cost more than a data breach or cyber security incident. Your priorities can change as a result. Maybe you find getting a GDPR fine more palatable than giving every single customer a refund!
Obviously, I’m not encouraging organisations to violate the law. The main point is that integrity and availability are just as important to preserve as confidentiality, yet are often overlooked.
While the disruption is ongoing, and your systems are unavailable, does that make you more vulnerable to other incidents? Or is it just a nuisance from a business point of view?
It definitely makes you more vulnerable to attack – because many of your controls will either be relaxed, or removed as part of your response
Plus, people will be panicking, and acting differently to normal. Their priorities have changed – suddenly, availability is the top priority, not security.
I suppose that, in a state of emergency, people are less discerning than they’d usually be. Did this make the social engineering attacks that followed the CrowdStrike incident more likely to succeed?
Yes. If you were a nation state actor, wanting to target an airport, this was a beautiful opportunity.
Put on a hi-vis jacket, pretend you’re from IT, and you can wander all over the terminals. Staff won’t think anything of it – you’re just there to get their systems back up.
Except that, while the attacker is working, they might:
- Deploy malware;
- Copy your system data; or
- Plant a keylogger or a rubber ducky [a USB stick that can log all activity done on a computer].
And no one would be any the wiser! Or not until much later, when the damage has already been done.
Turning black swan events into business opportunities
What are the business benefits for organisations that are prepared?
You can stand out from the crowd. That’s regardless of whether we’re talking black swan events like COVID-19, or really small things – being the only shop in town that takes cash payments when card payment systems are down, for example.
If you have a fragile business model, you’re at the mercy of being put out of action by the slightest thing – even a software update that went bad.
But if you have proper business continuity and disaster recovery measures in place, you can flip these events on their head. You can turn it into a massive advantage – being the organisation still standing while your competitors are all down. Or being the first to get back up.
Again, stand out from the crowd. Take the opportunity to build an immense amount of trust with your customers and partners.
Need help with your business continuity measures?
When disaster strikes, make sure you can act fast. Better still, learn to turn disruptive incidents into opportunities.
If you need expert advice on how to plan your business continuity management project, implement ISO 22301, or anything else related to business continuity, we can help.
About Adam Seamons
Adam is the information security manager of GRC International Group PLC, IT Governance’s parent company, after nearly 20 years’ experience working as a systems engineer and in technical support.
He also holds various certifications, including:
We’ve previously interviewed Adam about zero-trust architecture and cyber defence in depth.
We hope you enjoyed this edition of our ‘Expert Insight’ series. We’ll be back soon, chatting to another expert within GRC International Group.
If you’d like to get our latest interviews and resources straight to your inbox, subscribe to our free Security Spotlight newsletter.
Alternatively, explore our full index of interviews here.
